
1.1. What is Redshift
- Redshift is a custom build database in AWS environment.
- Redshift is a fully managed data warehouse database used for storing large amounts of data for business intelligence applications.
- Redshift uses “Simple SQL” language.
1.2. Cost
- Start a .25/hour, about $1000/TB
- Instance types:
- DC1 - use SSD scalel from 160GB to 326TB
- DC2 - use HHD, scale from 2TB to 2PB
- Storage is provisioned as part of the node. AWS charge by the node.
- You can use on-demand or reserved instance types no spot instance is allowed.
- You can mix on-demand and reserved instance in a cluster.
- You can shut down a cluster if it is not being used. When the cluster is restarted, the data will be loaded from the final snapshot stored on S3.
2. Redshift Architecture
2.1. Single or multi-nodes setup
- Redshift itself can be a single node or multi-nodes cluster.
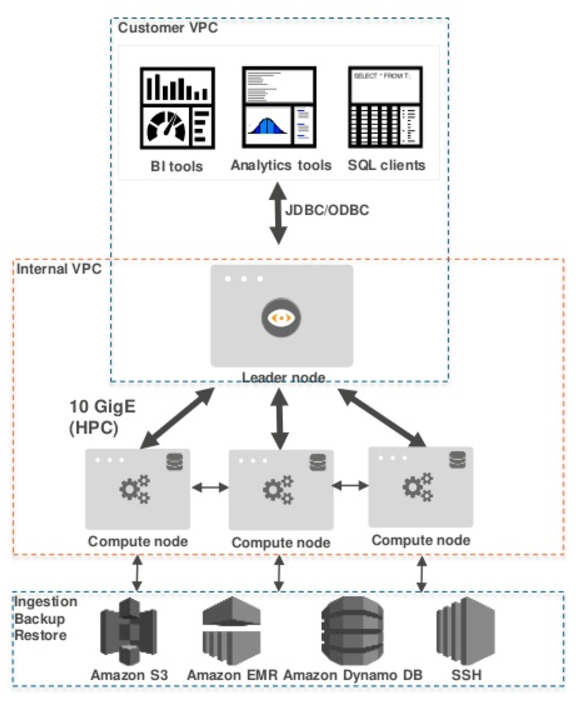
- You can access the database with AWS SDK or tools use JDBC/ODBC. When a user access redshift with an SQL statement:
- Redshte distributes the query from the “leader” node in parallel across all the cluster’s compute nodes
- The compute nodes work together to execute the queries and return the data back to the leader node which then organized the resift and send it back to the client requesting the data from the cluster.
The following diagram shows a multi-node Redshift setup
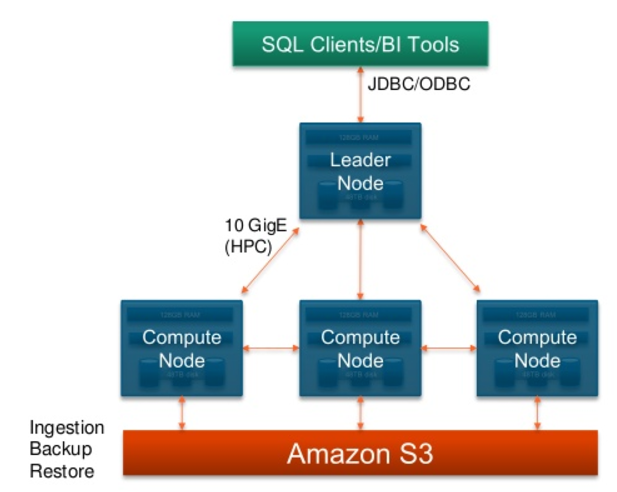 |
Functions of different component
- Leader node
- Simple SQL endpoint
- Store metadata
- Optimized query plan
- Coordinate query execution
- Local columnar storage
- Parallel/distributed execution of all queries
- Backup, restore, resizes
- S3 - store the snapshot
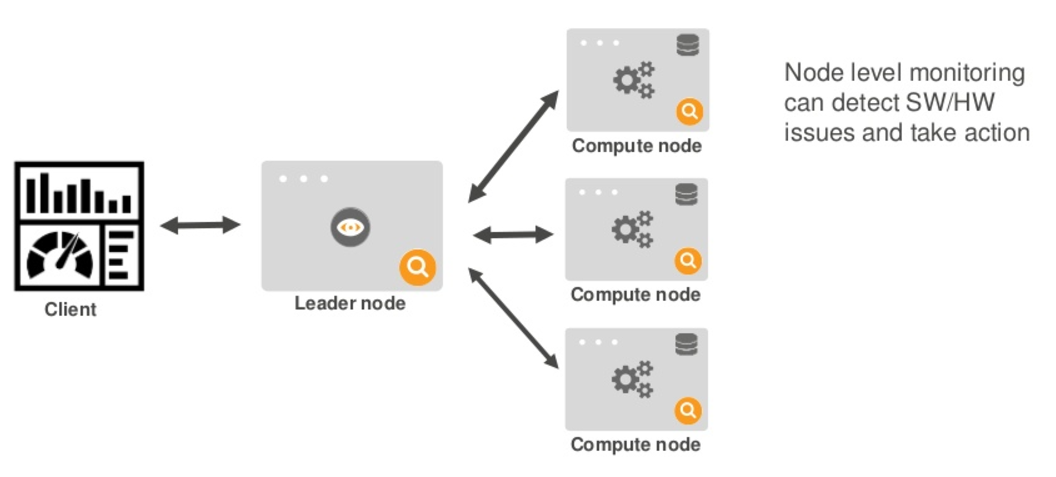
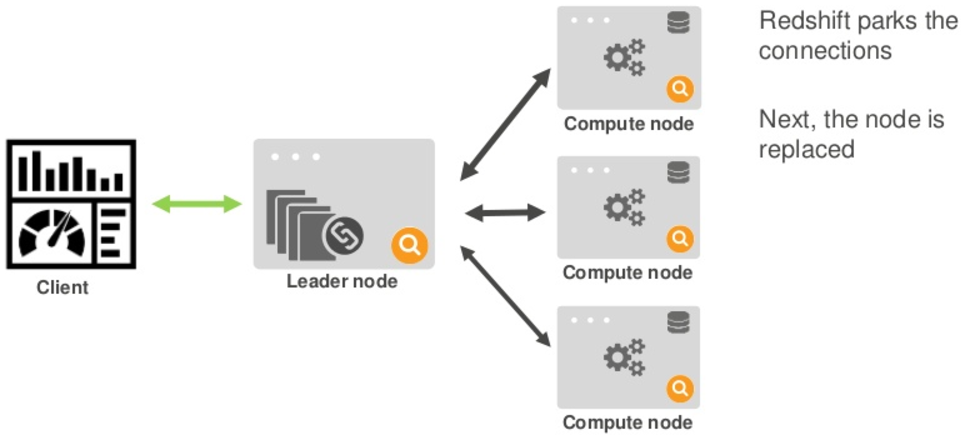
2.2. Redshift node fault tolerance
Redshift runs in a single AZ only, no multi-AZ setup.
Although there is no HA setup over multi-AZ, Redshift nodes are continuously backed up to AWS S3 and in the event of a failed node in the cluster, Redshift will replace the nodes and restore the data from backup.
The following diagrams illustrate how Redshift perform node recovery
 |
 |
 |
 |
3. Resizing Redshift
Scalability is the key advantage of using Redshift in AWS:
- We can start with a small single node cluster and scale up to larger and multi-node cluster as demain increased
- You can choose different instance type for redshift, each instance type has different cpu power and storage.
- As the performance or capacity (storage) needs changes, all you need to do is changing the number of of nodes/instance type.
- Amazon Redshift allow you to change the cluster size that with CLI or with a few clicks on the console
- During the process of resizing, the existing cluster is placed on the read only mode and the data will be copied from that to the new one in parallel. The queries against the old one can be performed even with the new one being provisioned. Amazon Redshift removes the old cluster when the new one is provisioned.
The following diagram illustrate adding a data node to a cluster

4. Redshift cluster shutdown vs delete
- Amazon Redshift perform regular automated backups. It is called automated Snapshot feature. It continuously backs up data on the cluster to Amazon S3. It is a continuous, incremental and automatic backing up of data. Amazon Redshift does it for a user defined period such as one to thirty-five days.
- When you shut down a Redshift cluster, a final snapshot will be made.
- When you delete a Redshift cluster, no final snapshot will be created
- Both shutdown or delete will remove the all automated snapshots. Except the final snapshot if you had shutdown the cluster.
- So if a Redshift was deleted, you can not recover database unless you had performed a manual snapshot before it was deleted.
5. Redshift backup and restore
5.1. Using Redshift snapshots
- Point-in-time snapshots are stored to S3 by Redshift automatically. User define the frequency of the snapshots during cluster configuration.
- A snapshot contain the following data
- Cluster configuration:
- Number of nodes
- Type of nodes
- Decryption keys
- Database data
- For cluster backup, we can use Redshift data snapshots.
- User can initial a manual snapshot.
- User can restore a Redshift DB from snapshot by launching a new cluster and importing the data from the snapshot

5.2. Using flat files
You can use Redshift SQL statements to import or export Database with files:
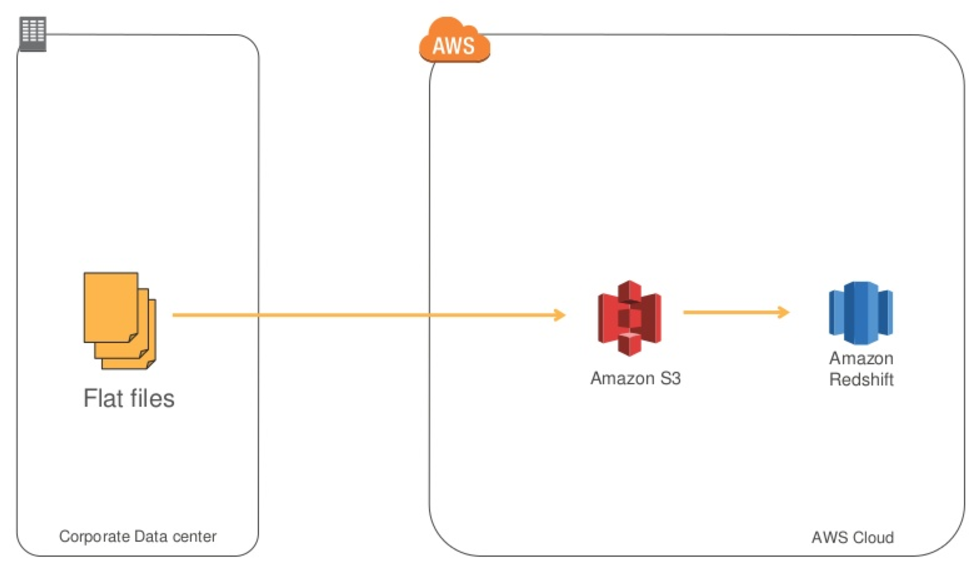
- You can use multiple files for input to maximize throughput.
6. DR consideration
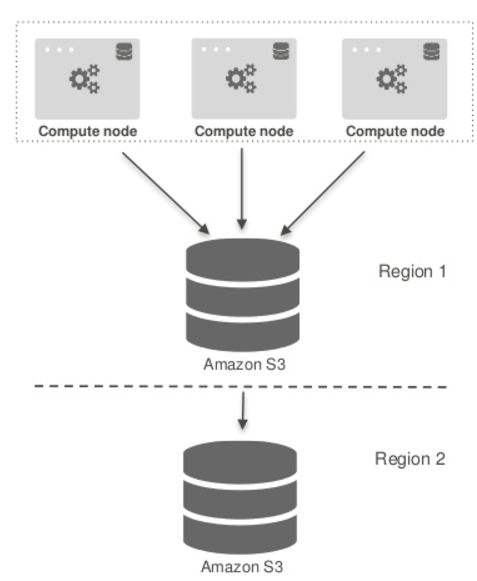
Snapshots can be copied from one region to another
- Manual Copy : user can copy the snapshot manually
- Automatic Copy: Redshift can be setup with automatically copy a snapshot from one region to another.
- User can setup retention period for how long to save the automatically copied. Snapshots
- Customer needs to pay for data transfer charge for copying data between regions.
The following diagram illustrate Redshift cross region data copy
7. Security is build-in
- All blocks on disk and S3 are encrypted
- SSL is used in between data in transit
- VPC for network isolation
- Audit logging with CloudTrail
Very nice blog... I found this information very useful. Also find the importance of AWS database snapshot. Thanks for sharing
ReplyDeleteThanks for sharing this wonderful content.its very useful to us.I gained many unknown information, the way you have clearly explained is really fantastic.This is incredible,I feel really happy to have seen your webpage
ReplyDeleteoracle training in chennai
oracle training institute in chennai
oracle training in bangalore
oracle training in hyderabad
oracle training
hadoop training in chennai
hadoop training in bangalore
The main focus of the data warehouse service provider is to create a well-maintained environment for daily monitoring of the tasks.
ReplyDeleteNice blog, Very useful to the users for more information
ReplyDeleteDevOps Training
DevOps Online Training
Amazon Redshift is widely used in the financial services industry, and it’s also used in research and retail. Amazon Redshift uses columnar storage, which stores data in columns rather than in rows. It can process petabytes of data and deliver query results in seconds. Read More
ReplyDelete